Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
@article{Saharia2022PhotorealisticTD,
title={Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding},
author={Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David J. Fleet and Mohammad Norouzi},
journal={ArXiv},
year={2022},
volume={abs/2205.11487},
url={https://api.semanticscholar.org/CorpusID:248986576}
}This work presents Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding, and finds that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment.
Figures and Tables from this paper

figure 1 
figure 2 
table 2 
figure 3 
figure 4 
figure A.1 
table A.1 
figure A.10 
figure A.11 
figure A.12 
figure A.13 
figure A.14 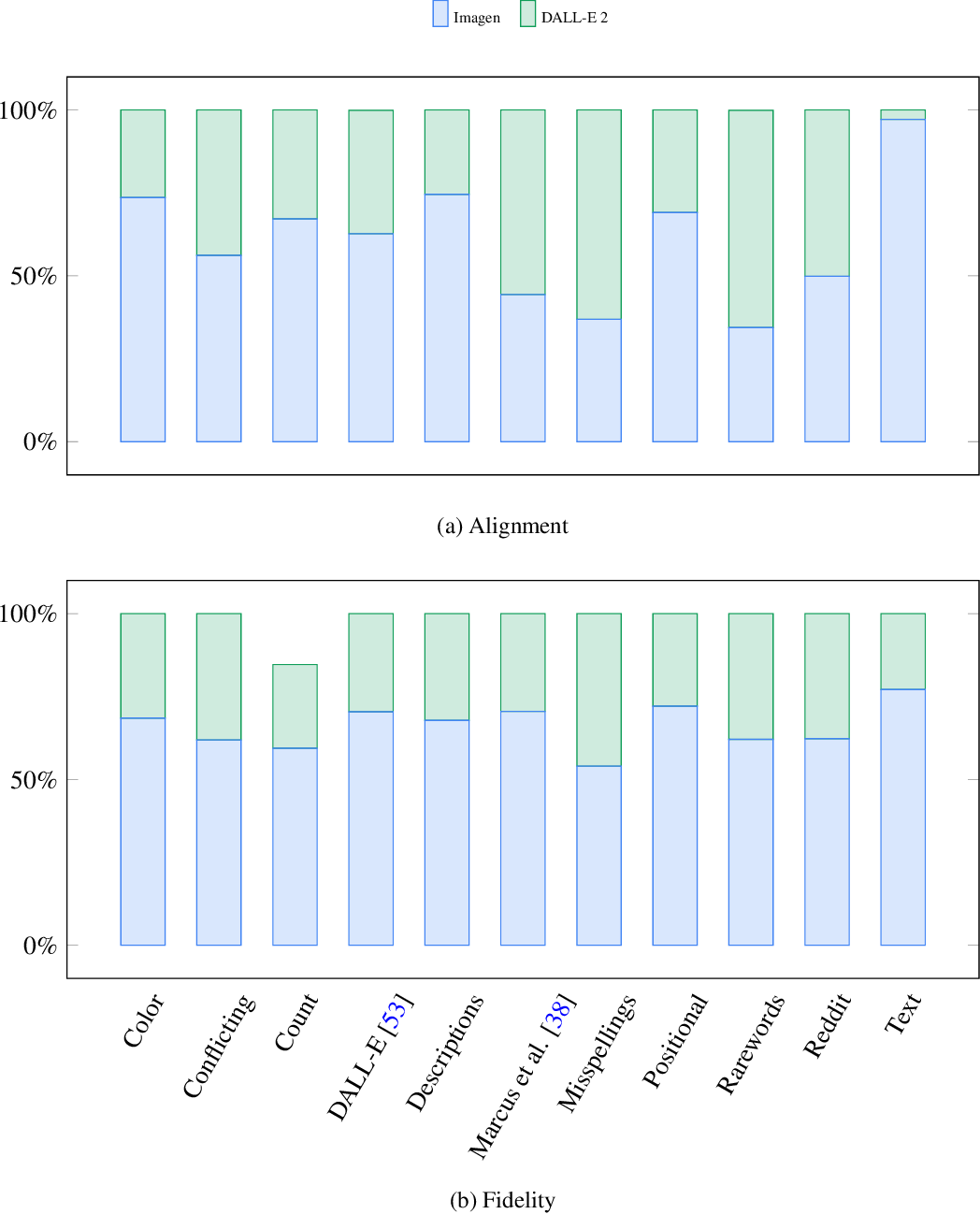
figure A.15 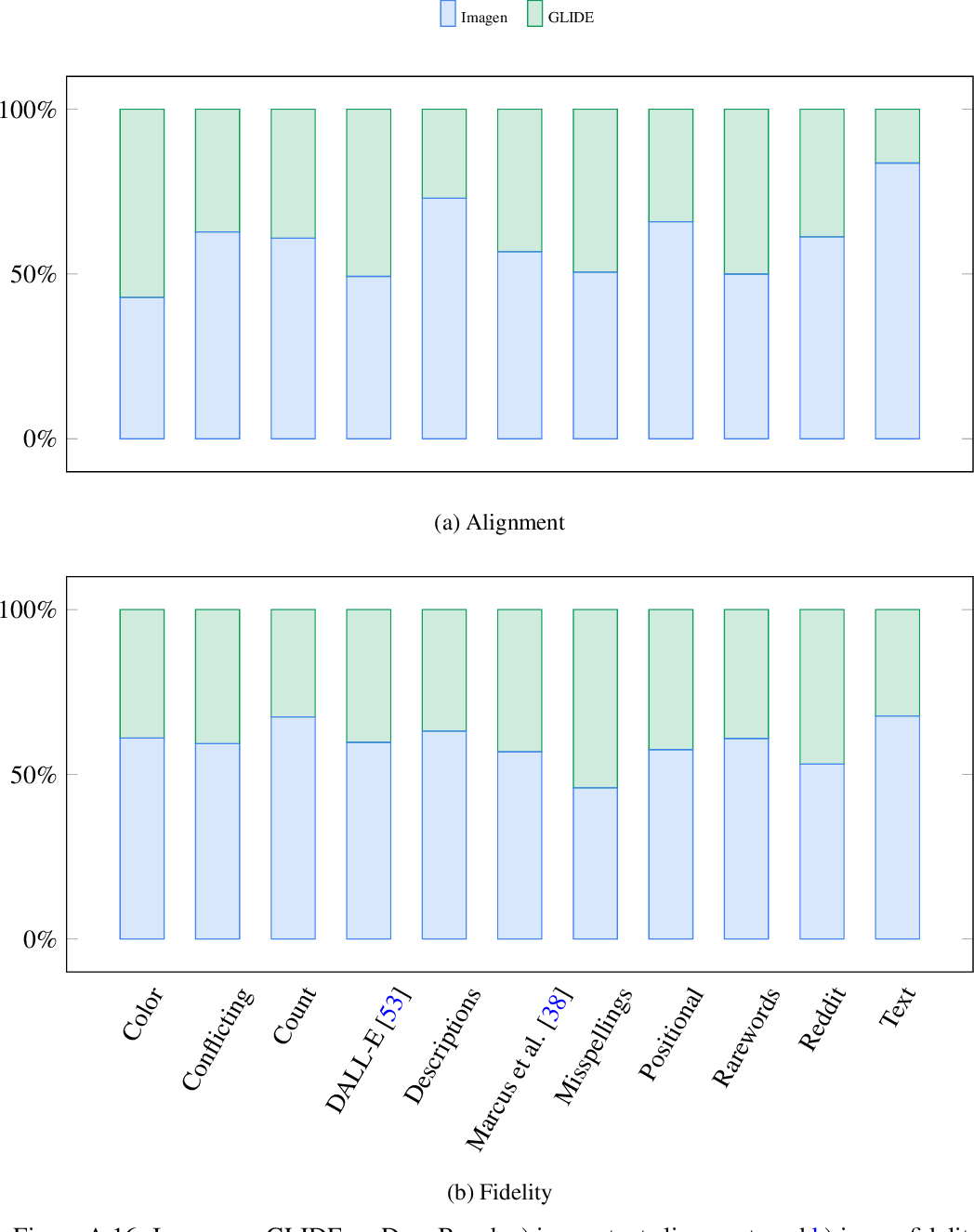
figure A.16 
figure A.17 
figure A.18 
figure A.19 
figure A.2 
figure A.20 
figure A.21 
figure A.22 
figure A.23 
figure A.24 
figure A.25 
figure A.26 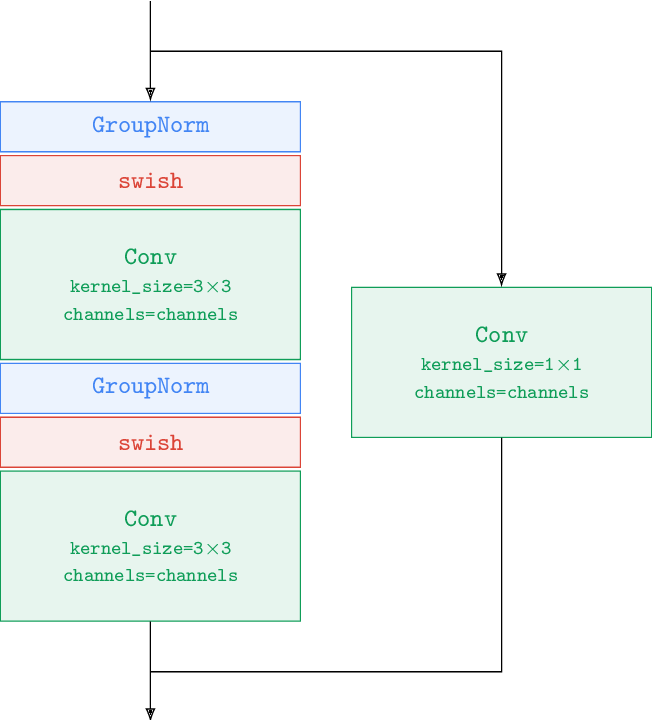
figure A.27 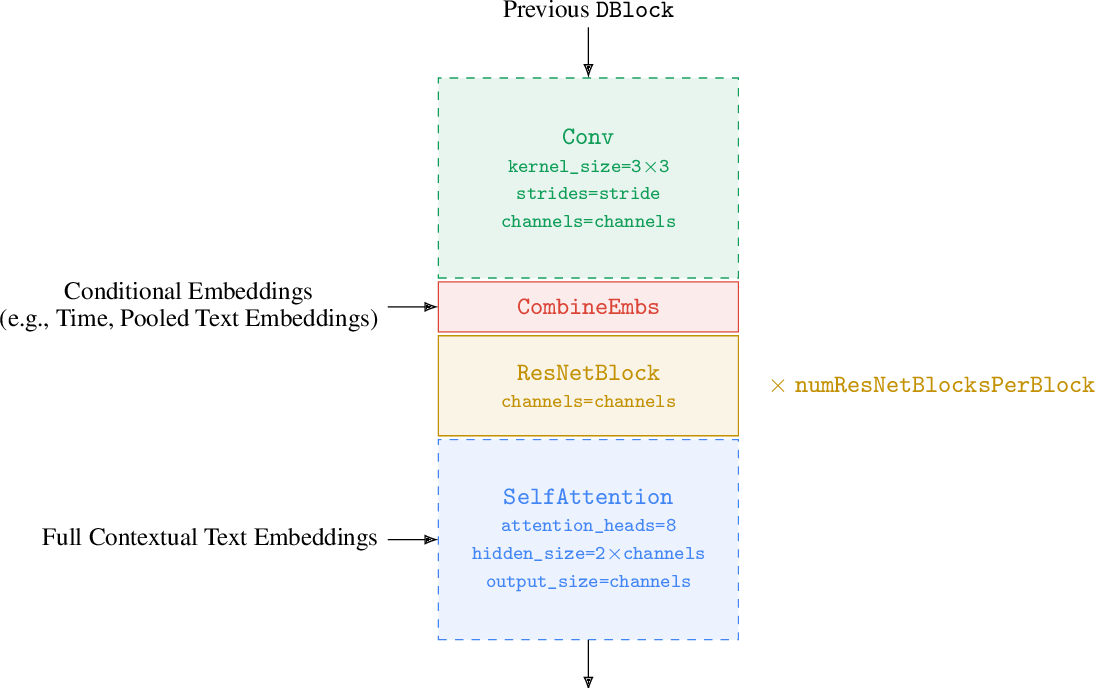
figure A.28 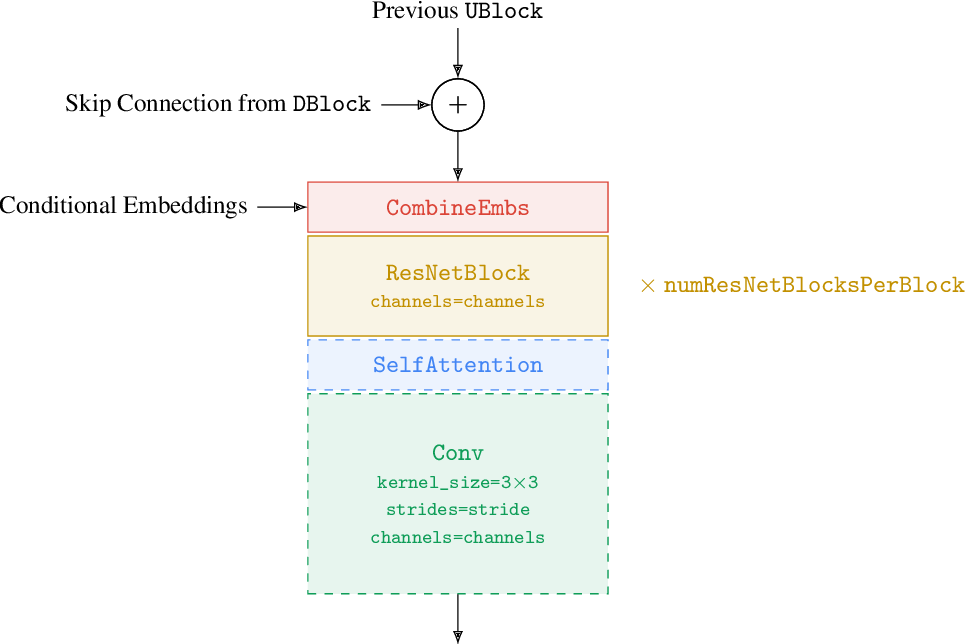
figure A.29 
figure A.3 
figure A.30 
figure A.4 
figure A.5 
figure A.6 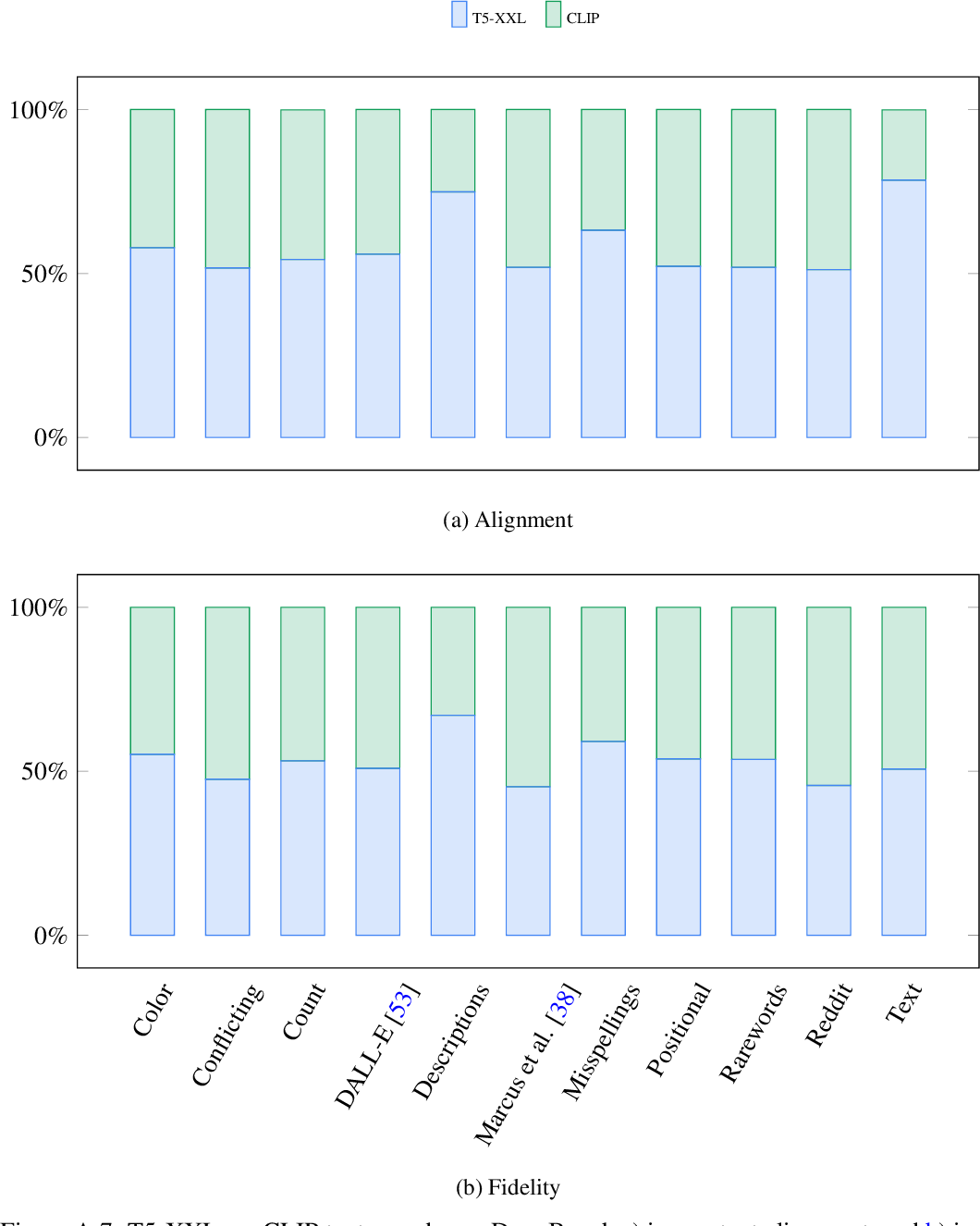
figure A.7 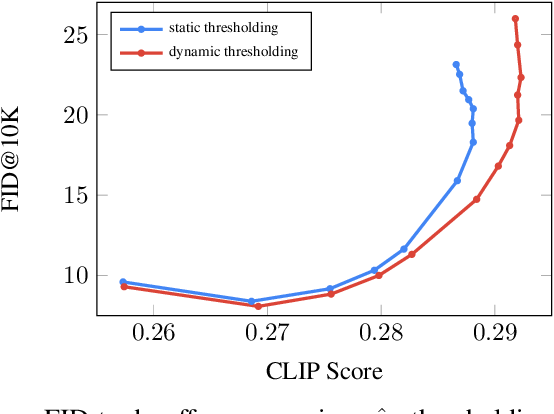
figure A.8 
figure A.9
Topics
Imagen (opens in a new tab)DrawBench (opens in a new tab)DALL-E 2 (opens in a new tab)Text-to-Image (opens in a new tab)Text-to-image Models (opens in a new tab)Diffusion Models (opens in a new tab)Guidance Weights (opens in a new tab)Text-to-Image Diffusion Models (opens in a new tab)Text To Image Synthesis (opens in a new tab)Text Conditioning (opens in a new tab)
7,210 Citations
Unleashing Text-to-Image Diffusion Models for Visual Perception
- 2023
Computer Science
It is shown that vision-language pre-trained diffusion models can be faster adapted to downstream visual perception tasks using the proposed VPD, a new framework that exploits the semantic information of a pre-trained text-to-image diffusion model in visual perception tasks.
RenAIssance: A Survey Into AI Text-to-Image Generation in the Era of Large Model
- 2025
Computer Science
It is argued that TTI development could yield impressive productivity improvements for creation, particularly in the context of the AIGC era, and could be extended to more complex tasks such as video generation and 3D generation.
Paragraph-to-Image Generation with Information-Enriched Diffusion Model
- 2025
Computer Science
An information-enriched diffusion model for paragraph-to-image generation task, termed ParaDiffusion, is introduced, which delves into the transference of the extensive semantic comprehension capabilities of large language models to the task of image generation.
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
- 2023
Computer Science
A new framework is presented that takes text-to- image synthesis to the realm of image- to-image translation, where features extracted from the guidance image are directly injected into the generation process of the translated image, requiring no training or fine-tuning.
Improving Compositional Text-to-image Generation with Large Vision-Language Models
- 2023
Computer Science
The proposed methodology significantly improves text-image alignment in compositional image generation, particularly with respect to object number, attribute binding, spatial relationships, and aesthetic quality.
Image-dev: An Advance Text to Image AI model
- 2022
Computer Science
Image-dev is a Text-To-Image model that blends TF-IDF(Term Frequency - Inverse Document Frequency) model along with preposition model, to evaluate the relation between the data object to produce conflict category images.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
- 2022
Computer Science
The Pathways Autoregressive Text-to-Image (Parti) model is presented, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge and explores and highlights limitations of the models.
Kandinsky: an Improved Text-to-Image Synthesis with Image Prior and Latent Diffusion
- 2023
Computer Science
Kandinsky1, a novel exploration of latent diffusion architecture, combining the principles of the image prior models with latent diffusion techniques is presented, marking this model as the top open-source performer in terms of measurable image generation quality.
Swinv2-Imagen: hierarchical vision transformer diffusion models for text-to-image generation
- 2023
Computer Science
The Swinv2-Imagen model is proposed, a novel text-to-image diffusion model based on a Hierarchical Visual Transformer and a Scene Graph incorporating a semantic layout that outperforms several popular state-of-the-art methods.
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
- 2022
Computer Science
UPainting is proposed, which combines the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, and greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes.
108 References
Palette: Image-to-Image Diffusion Models
- 2022
Computer Science
A unified framework for image-to-image translation based on conditional diffusion models is developed and it is shown that a generalist, multi-task diffusion model performs as well or better than task-specific specialist counterparts.
Hierarchical Text-Conditional Image Generation with CLIP Latents
- 2022
Computer Science
It is shown that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity, and the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion.
Towards Language-Free Training for Text-to-Image Generation
- 2022
Computer Science
The first work to train text-to-image generation models without any text data is proposed, which leverages the well-aligned multi-modal semantic space of the powerful pre-trained CLIP model: the requirement of text-conditioning is seamlessly alleviated via generating text features from image features.
Improving Text-to-Image Synthesis Using Contrastive Learning
- 2021
Computer Science
Experimental results have shown that the contrastive learning approach can effectively improve the quality and enhance the semantic consistency of synthetic images in terms of three metrics: IS, FID and R-precision.
DiffusionCLIP: Text-guided Image Manipulation Using Diffusion Models
- 2021
Computer Science
A novel DiffusionCLIP is presented which performs text-driven image manipulation with diffusion models using Contrastive Language–Image Pre-training (CLIP) loss and has a performance comparable to that of the modern GAN-based image processing methods for in and out-of-domain image processing tasks.
CoCa: Contrastive Captioners are Image-Text Foundation Models
- 2022
Computer Science
Contrastive Captioner (CoCa), a minimalist design to pretrain an image-text encoder-decoder foundation model jointly with contrastive loss and captioning loss, thereby subsuming model capabilities from contrastive approaches like CLIP and generative methods like SimVLM.
DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-To-Image Synthesis
- 2019
Computer Science
The proposed DM-GAN model introduces a dynamic memory module to refine fuzzy image contents, when the initial images are not well generated, and performs favorably against the state-of-the-art approaches.
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
- 2022
Computer Science
This work proposes a novel text-to-image method that addresses gaps in applicability and quality by enabling a simple control mechanism complementary to text in the form of a scene, and introducing elements that substantially improve the tokenization process by employing domain-specific knowledge over key image regions.
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- 2022
Computer Science
This work explores diffusion models for the problem of text-conditional image synthesis and compares two different guidance strategies: CLIP guidance and classifier-free guidance, finding that the latter is preferred by human evaluators for both photorealism and caption similarity, and often produces photorealistic samples.
Cross-Modal Contrastive Learning for Text-to-Image Generation
- 2021
Computer Science
The Cross-Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses the challenge of text-to-image synthesis systems by maximizing the mutual information between image and text via multiple contrastive losses which capture inter- modality and intra-modality correspondences.