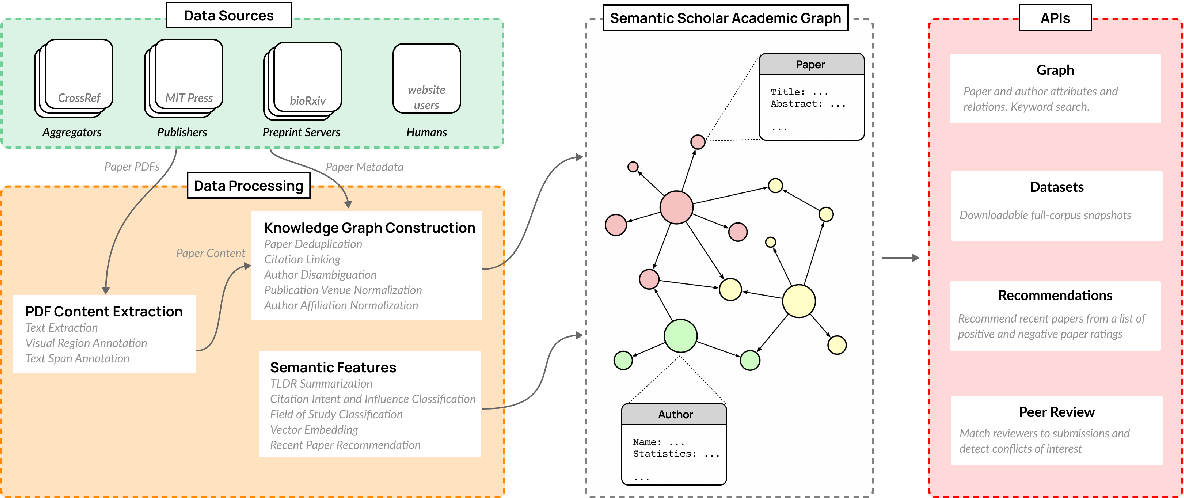
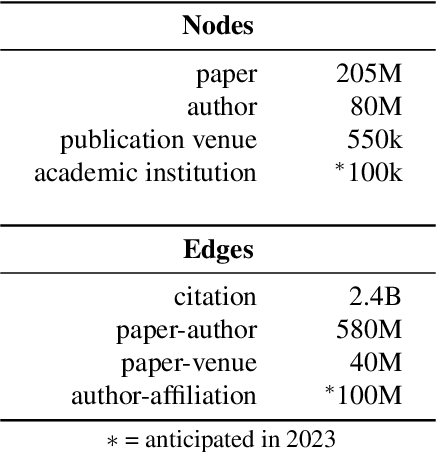
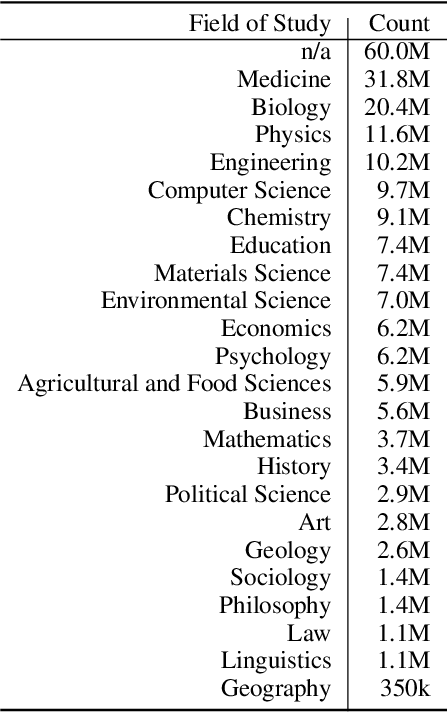
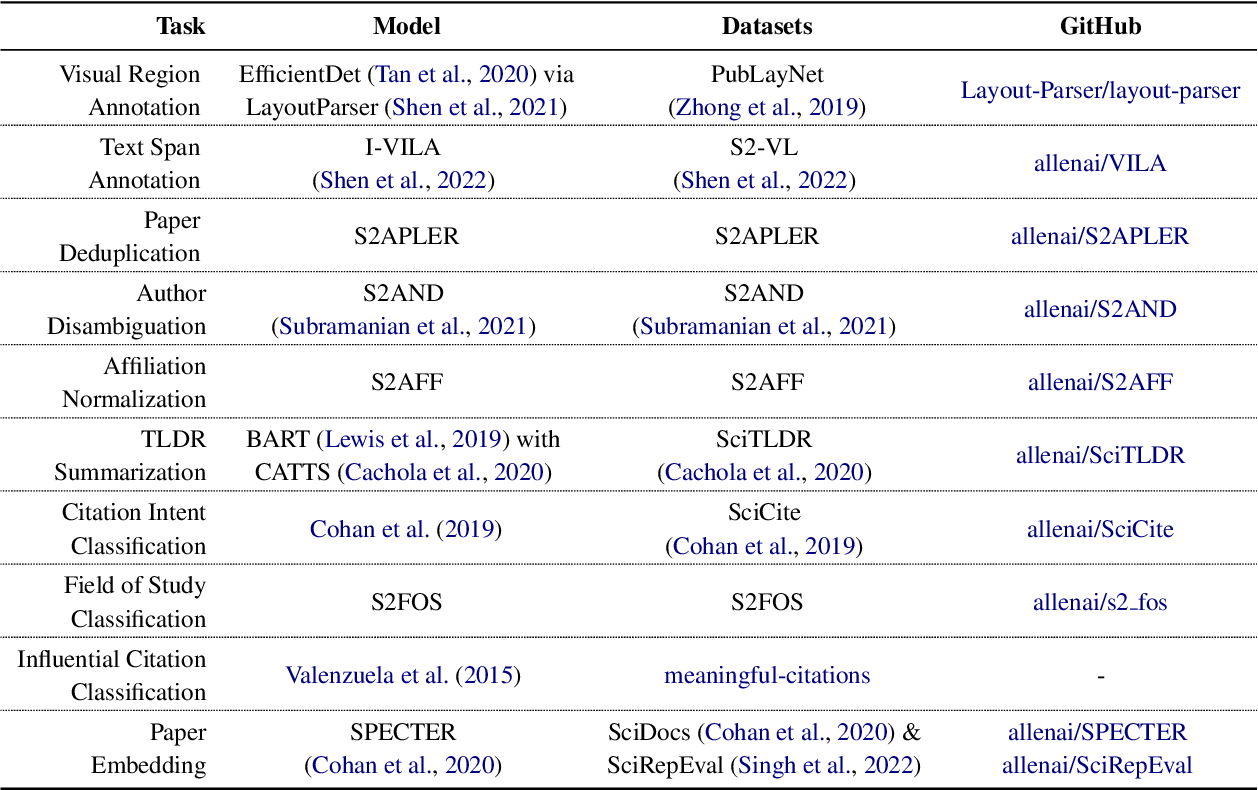
The Semantic Scholar Open Data Platform
@article{Kinney2023TheSS,
title={The Semantic Scholar Open Data Platform},
author={Rodney Michael Kinney and Chloe Anastasiades and Russell Authur and Iz Beltagy and Jonathan Bragg and Alexandra Buraczynski and Isabel Cachola and Stefan Candra and Yoganand Chandrasekhar and Arman Cohan and Miles Crawford and Doug Downey and Jason Dunkelberger and Oren Etzioni and Rob Evans and Sergey Feldman and Joseph Gorney and David W. Graham and F.Q. Hu and Regan Huff and Daniel King and Sebastian Kohlmeier and Bailey Kuehl and Michael Langan and Daniel Lin and Haokun Liu and Kyle Lo and Jaron Lochner and Kelsey MacMillan and Tyler C. Murray and Christopher Newell and Smita R Rao and Shaurya Rohatgi and Paul Sayre and Shannon Zejiang Shen and Amanpreet Singh and Luca Soldaini and Shivashankar Subramanian and A. Tanaka and Alex D Wade and Linda M. Wagner and Lucy Lu Wang and Christopher Wilhelm and Caroline Wu and Jiangjiang Yang and Angele Zamarron and Madeleine van Zuylen and Daniel S. Weld},
journal={ArXiv},
year={2023},
volume={abs/2301.10140},
url={https://api.semanticscholar.org/CorpusID:256194545}
}This paper combines public and proprietary data sources using state-of-theart techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date.
133 Citations
The Semantic Reader Project
- 2024
Computer Science
The Semantic Reader Project is described, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers, and a collection of novel reading interfaces are developed and evaluated and evaluated them with study participants and real-world users to show improved reading experiences for scholars.
Toward Robust URL Extraction for Open Science: A Study of arXiv File Formats and Temporal Trends
- 2025
Computer Science
It is suggested that using a combination of multiple formats achieves better performance on URL extraction than a single format, and the number of URLs in arXiv papers has been steadily increasing since 1992 to 2014 and has been drastically increasing from 2014 to 2024.
MIR: Methodology Inspiration Retrieval for Scientific Research Problems
- 2025
Computer Science
Through extensive ablation studies and qualitative analyses, the promise of MIR is exhibited in enhancing automated scientific discovery and outline avenues for advancing inspiration-driven retrieval.
FoRC4CL: A Fine-grained Field of Research Classification and Annotated Dataset of NLP Articles
- 2024
Computer Science, Linguistics
A corpus of 1,500 ACL Anthology publications annotated with their main contributions is constructed using a novel hierarchical taxonomy of core CL/NLP topics and sub-topics to classify papers into their respective sub-topics.
On the Effectiveness of Large Language Models in Automating Categorization of Scientific Texts
- 2025
Computer Science
Evaluating a variety of LLMs in their ability to sort scientific publications into hierarchical classifications systems finds that recent LLMs (such as Meta Llama 3.1) are able to reach an accuracy of up to 0.82, which is up to 0.08 better than traditional BERT models.
S2abEL: A Dataset for Entity Linking from Scientific Tables
- 2023
Computer Science
A neural baseline method designed for EL is introduced on scientific tables containing many out-of-knowledge-base mentions, and it significantly outperforms a state- of-the-art generic table EL method.
The OpenCitations Index: description of a database providing open citation data
- 2024
Computer Science
This article presents the OpenCitations Index, a collection of open citation data maintained by OpenCitations, an independent, not-for-profit infrastructure organisation for open scholarship…
CS-PaperSum: A Large-Scale Dataset of AI-Generated Summaries for Scientific Papers
- 2025
Computer Science
CS-PaperSum is introduced, a large-scale dataset of 91,919 papers from 31 top-tier computer science conferences, enriched with AI-generated structured summaries using ChatGPT, providing a valuable resource for researchers, policymakers, and scientific information retrieval systems.
Content Aware Analysis of Scholarly Networks: A Case Study on CORD19 Dataset
- 2024
Computer Science
This paper introduces a novel approach to use semantic information through the HITS algorithm-based propagation of topic information in the network, and shows that incorporating topic data significantly influences article rankings, revealing deeper insights into the structure of the academic community.
The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing Practices
- 2023
Physics, Computer Science
A large-scale dataset of 1.1M papers from arXiv that are representative of the fields of physics, math, and computer science is analyzed to analyze the adoption of data and method link-sharing practices over time and their impact on article reception.
19 References
S2ORC: The Semantic Scholar Open Research Corpus
- 2020
Computer Science
In S2ORC, a large corpus of 81.1M English-language academic papers spanning many academic disciplines is introduced, which is expected to facilitate research and development of tools and tasks for text mining over academic text.
Construction of the Literature Graph in Semantic Scholar
- 2018
Computer Science
This paper reduces literature graph construction into familiar NLP tasks, point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task.
Structural Scaffolds for Citation Intent Classification in Scientific Publications
- 2019
Computer Science
This work proposes structural scaffolds, a multitask model to incorporate structural information of scientific papers into citations for effective classification of citation intents, which achieves a new state-of-the-art on an existing ACL anthology dataset with a 13.3% absolute increase in F1 score.
An Overview of Microsoft Academic Service (MAS) and Applications
- 2015
Computer Science
A knowledge driven, highly interactive dialog that seamlessly combines reactive search and proactive suggestion experience, and a proactive heterogeneous entity recommendation are demonstrated.
S2AND: A Benchmark and Evaluation System for Author Name Disambiguation
- 2021
Computer Science
This work presents S2AND, a unified benchmark dataset for AND on scholarly papers, as well as an open-source reference model implementation, and releases the unified dataset, model code, trained models, and evaluation suite to the research community.
Identifying Meaningful Citations
- 2015
Computer Science
This work introduces the novel task of identifying important citations in scholarly literature, i.e., citations that indicate that the cited work is used or extended in the new effort, and proposes a supervised classification approach that addresses this task with a battery of features.
PubLayNet: Largest Dataset Ever for Document Layout Analysis
- 2019
Computer Science
The PubLayNet dataset for document layout analysis is developed by automatically matching the XML representations and the content of over 1 million PDF articles that are publicly available on PubMed Central and demonstrated that deep neural networks trained on Pub LayNet accurately recognize the layout of scientific articles.
SciBERT: A Pretrained Language Model for Scientific Text
- 2019
Computer Science, Biology
SciBERT leverages unsupervised pretraining on a large multi-domain corpus of scientific publications to improve performance on downstream scientific NLP tasks and demonstrates statistically significant improvements over BERT.
SPECTER: Document-level Representation Learning using Citation-informed Transformers
- 2020
Computer Science
This work proposes SPECTER, a new method to generate document-level embedding of scientific papers based on pretraining a Transformer language model on a powerful signal of document- level relatedness: the citation graph, and shows that Specter outperforms a variety of competitive baselines on the benchmark.
SciRepEval: A Multi-Format Benchmark for Scientific Document Representations
- 2023
Computer Science, Biology
It is shown how state-of-the-art models like SPECTER and SciNCL struggle to generalize across the task formats, and that simple multi-task training fails to improve them, and a new approach that learns multiple embeddings per document, each tailored to a different format, can improve performance.