Longformer: The Long-Document Transformer
@article{Beltagy2020LongformerTL,
title={Longformer: The Long-Document Transformer},
author={Iz Beltagy and Matthew E. Peters and Arman Cohan},
journal={ArXiv},
year={2020},
volume={abs/2004.05150},
url={https://api.semanticscholar.org/CorpusID:215737171}
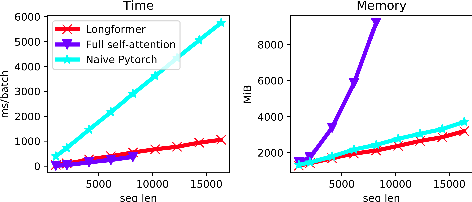
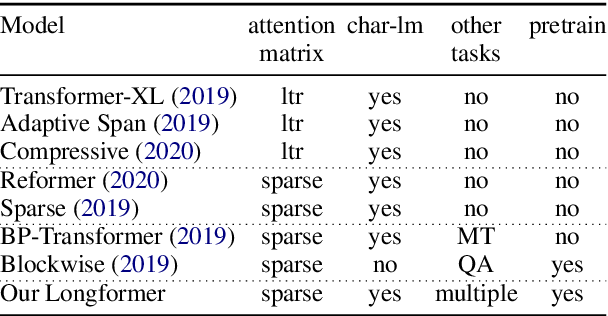
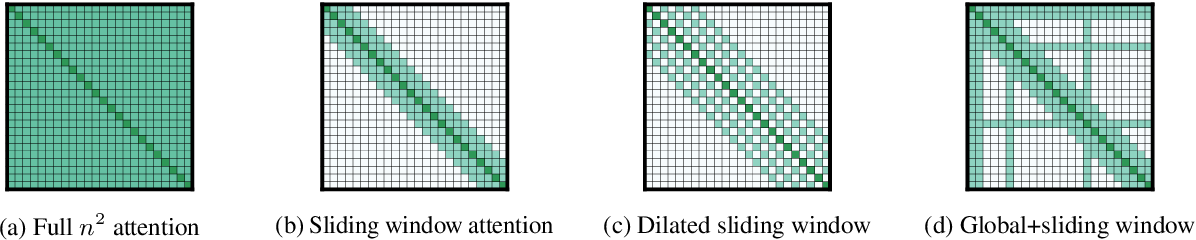
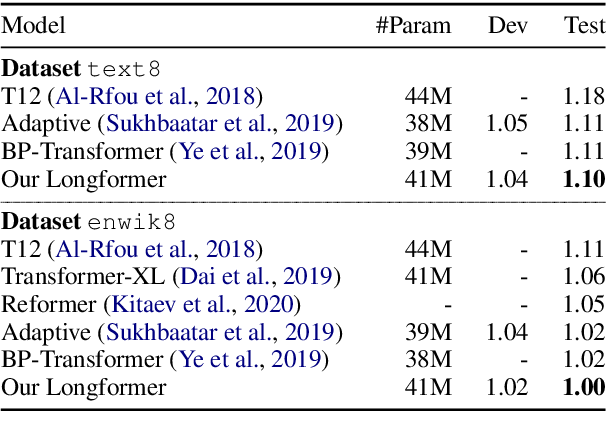
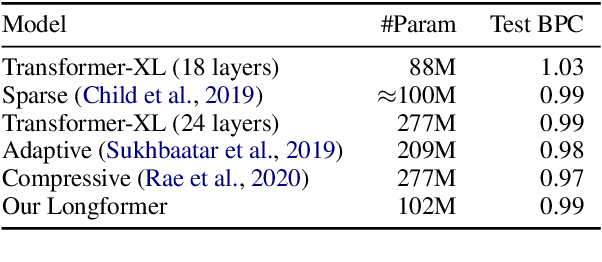
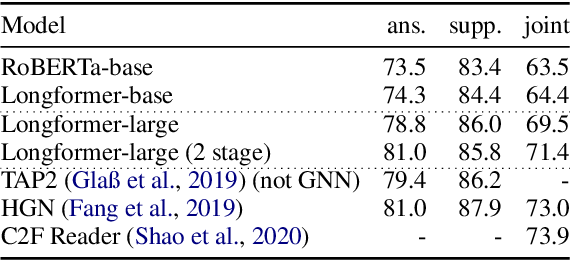
}Following prior work on long-sequence transformers, the Longformer is evaluated on character-level language modeling and achieves state-of-the-art results on text8 and enwik8 and pretrain Longformer and finetune it on a variety of downstream tasks.
Figures and Tables from this paper





Topics
Longformer (opens in a new tab)Long-Document Transformer (opens in a new tab)Sliding Window Attention (opens in a new tab)Dilated Sliding Window (opens in a new tab)Long Document Classification (opens in a new tab)Longformer-large (opens in a new tab)Global Attention (opens in a new tab)Blockwise Attention (opens in a new tab)Long Sequences (opens in a new tab)Sparse Attention Patterns (opens in a new tab)
4,704 Citations
LongT5-Mulla: LongT5 With Multi-Level Local Attention for a Longer Sequence
- 2023
Computer Science
This paper proposes multi-level local attention (Mulla attention), which is a hierarchical local attention that acts on both the input sequence and multiple pooling sequences of different granularity simultaneously, thus performing long-range modeling while maintaining linear or log-linear complexity.
LongT5: Efficient Text-To-Text Transformer for Long Sequences
- 2022
Computer Science
A new model, called LongT5, is presented, with which the effects of scaling both the input length and model size at the same time are explored, which mimics ETC's local/global attention mechanism, but without requiring additional side-inputs.
Long-Short Transformer: Efficient Transformers for Language and Vision
- 2021
Computer Science, Linguistics
This paper proposes Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks, and proposes a dual normalization strategy to account for the scale mismatch between the two attention mechanisms.
LongVQ: Long Sequence Modeling with Vector Quantization on Structured Memory
- 2024
Computer Science
A new method called LongVQ, which uses the vector quantization (VQ) technique to compress the global abstraction as a length-fixed codebook, enabling the linear-time computation of the attention matrix, and effectively maintains dynamic global and local patterns.
Efficient Long-Range Transformers: You Need to Attend More, but Not Necessarily at Every Layer
- 2023
Computer Science
MASFormer, an easy-to-implement transformer variant with Mixed Attention Spans, is proposed, which is equipped with full attention to capture long-range dependencies, but only at a small number of layers.
Long-Span Summarization via Local Attention and Content Selection
- 2021
Computer Science
This work exploits large pre-trained transformer-based models and address long-span dependencies in abstractive summarization using two methods: local self-attention; and explicit content selection, which can achieve comparable or better results than existing approaches.
Memformer: The Memory-Augmented Transformer
- 2020
Computer Science
Results show that Memformer outperforms the previous long-range sequence models on WikiText-103, including Transformer-XL and compressive Transformer, and is also compatible with other self-supervised tasks to further improve the performance on language modeling.
Memory transformer with hierarchical attention for long document processing
- 2021
Computer Science
A new version of transformer is introduced, a Sentence level transformer with global memory pooling and hierarchical attention to cope with long text and hypothesize that attaching memory slots to each sequence improves the quality of translation.
ERNIE-Doc: A Retrospective Long-Document Modeling Transformer
- 2021
Computer Science
Transformers are not suited for processing long documents, due to their quadratically increasing memory and time consumption. Simply truncating a long document or applying the sparse attention…
LNLF-BERT: Transformer for Long Document Classification With Multiple Attention Levels
- 2024
Computer Science
The theoretical analysis shows that the LNLF-BERT mechanism is an approximator of the full self-attention model, and the architecture is scalable to various downstream tasks, making it adaptable for different applications in natural language processing.
59 References
Generating Long Sequences with Sparse Transformers
- 2019
Computer Science
This paper introduces sparse factorizations of the attention matrix which reduce this to $O(n)$, and generates unconditional samples that demonstrate global coherence and great diversity, and shows it is possible in principle to use self-attention to model sequences of length one million or more.
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- 2020
Computer Science, Linguistics
BART is presented, a denoising autoencoder for pretraining sequence-to-sequence models, which matches the performance of RoBERTa on GLUE and SQuAD, and achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks.
Attention is All you Need
- 2017
Computer Science
A new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely is proposed, which generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
Transformer-XL: Attentive Language Models beyond a Fixed-Length Context
- 2019
Computer Science
This work proposes a novel neural architecture Transformer-XL that enables learning dependency beyond a fixed length without disrupting temporal coherence, which consists of a segment-level recurrence mechanism and a novel positional encoding scheme.
Big Bird: Transformers for Longer Sequences
- 2020
Computer Science
It is shown that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model.
BP-Transformer: Modelling Long-Range Context via Binary Partitioning
- 2019
Computer Science
Ad adopting a fine-to-coarse attention mechanism on multi-scale spans via binary partitioning (BP), BP-Transformer (BPT for short) is proposed, which has a superior performance for long text than previous self-attention models.
Pay Less Attention with Lightweight and Dynamic Convolutions
- 2019
Computer Science
It is shown that a very lightweight convolution can perform competitively to the best reported self-attention results, and dynamic convolutions are introduced which are simpler and more efficient than self-ATTention.
ETC: Encoding Long and Structured Inputs in Transformers
- 2020
Computer Science
A new Transformer architecture, Extended Transformer Construction (ETC), is presented that addresses two key challenges of standard Transformer architectures, namely scaling input length and encoding structured inputs.
Sequence to Sequence Learning with Neural Networks
- 2014
Computer Science
This paper presents a general end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure, and finds that reversing the order of the words in all source sentences improved the LSTM's performance markedly, because doing so introduced many short term dependencies between the source and the target sentence which made the optimization problem easier.
Span Selection Pre-training for Question Answering
- 2020
Computer Science
This paper introduces a new pre-training task inspired by reading comprehension to better align the pre- training from memorization to understanding, and shows that the proposed model has strong empirical evidence as it obtains SOTA results on Natural Questions, a new benchmark MRC dataset, outperforming BERT-LARGE by 3 F1 points on short answer prediction.